2024-8-24 服务器故障记录
事故概括
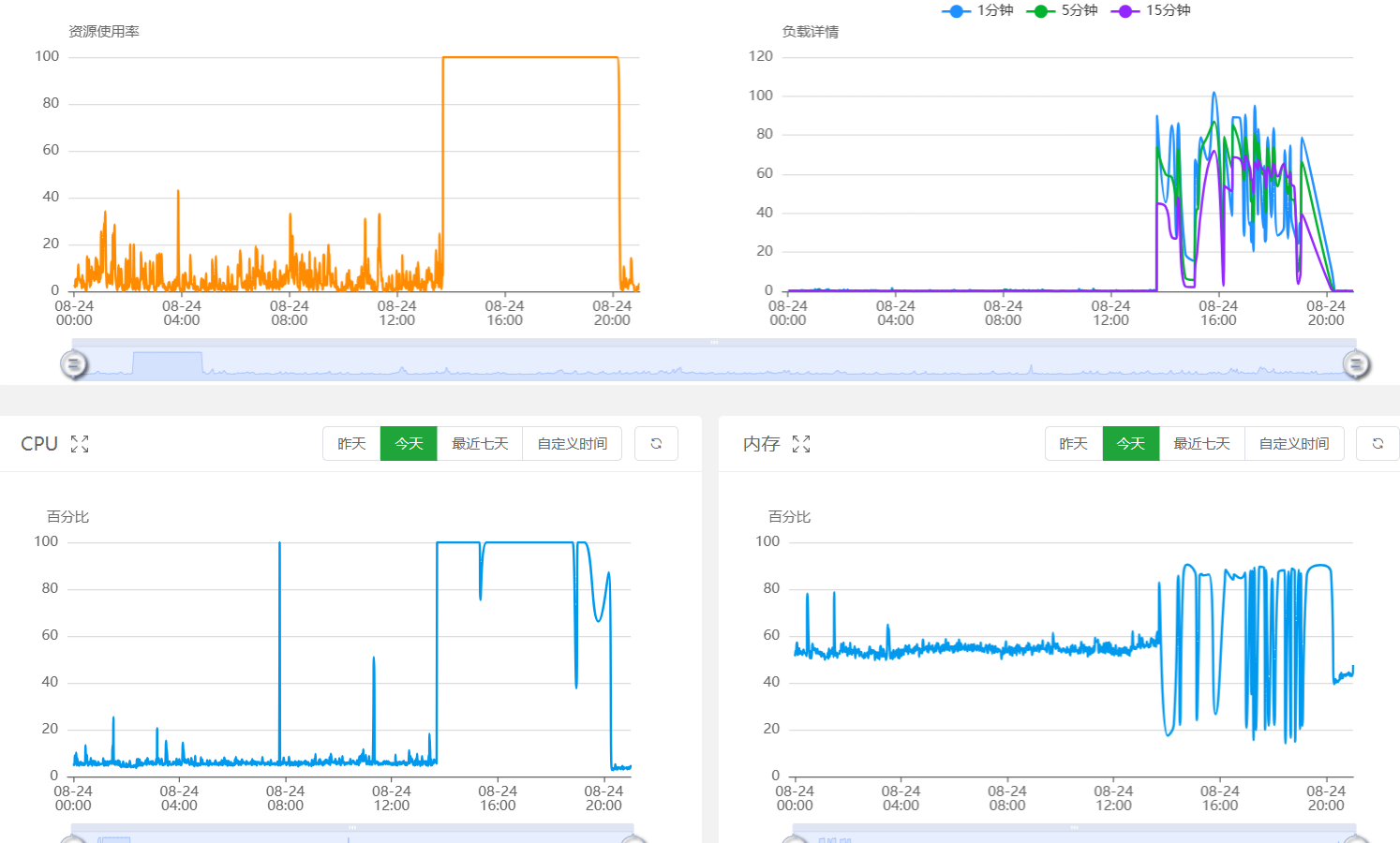
资源使用率自 2024-8-24 14:43:00 出现极大幅度的异常,资源使用率瞬间升值 100%,持续无下降至 2024-8-24 20:11,在采取措施后,资源使用率瞬间降至 20%,也就是正常业务水平。
负载从 14:43:00 开始升高,瞬间达到 90,然后维持在 90 ~ 50,正常负载为 0.2。
CPU 使用率从 14:43:00 瞬间攀升到 100%,然后基本上维持在这个程度,只有在重启服务器后的短暂的一分钟会下降,同样持续到 2024-8-24 20:11。
内存从同样的时间开始出现从 90% 到 20% 的大幅度持续波动,同样时间结束。
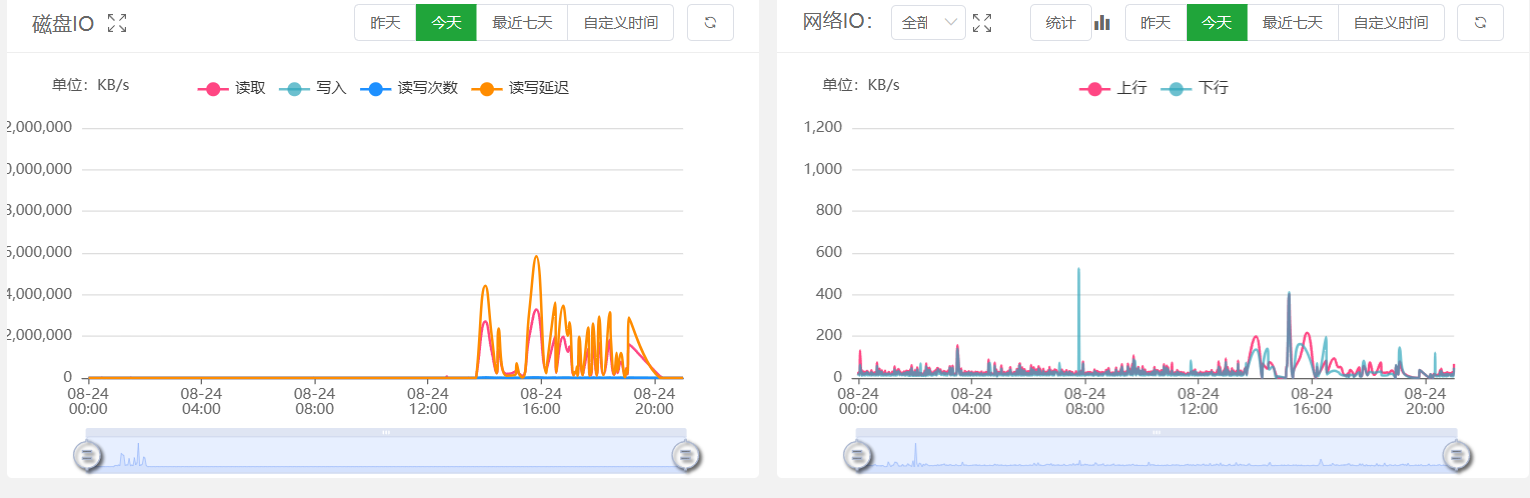
磁盘 IO 远远高于正常水平,从原来的 100 KB/s 攀升至 328.6 MB/s 左右的程。
网络 IO 正常。
经过
下午四点半,我在机房准备看看我的博客的时候发现竟然访问超时。我打开邮箱,发现腾讯云和 Uptimerobot 都给我发送邮件,显示网站异常,其中腾讯云的监控是直接监控源站的。
我登录了雷池 WAF 后台,发现访问正常,也就排除了 WAF 的问题。
我登录了 CDN 后台,也没有发现大流量的 DDOS / CC,那么也排除了攻击的问题。
我尝试登录服务器,发现完全登录不上,于是登录腾讯云的控制台进行重启。
重启后,发现服务器没过多久恢复原样,说明故障的进程是开机自启动的。
没办法,ssh 连接不上,我就直接找了腾讯云的客服。
在经过必要的授权后,我直接把服务器的问题交给腾讯云客服的专业人员去调试了,我就先做其他事情了。
过了大约几十分钟,我查看的时候发现腾讯云客服已经回复了,说找到了故障进程,而且帮助我杀掉了。
我打开业务一看,确实好了,原来是通过 VNC 登录,找到问题然后 kill 掉了。原来是 Hfish 蜜罐的锅。
给腾讯云的客服和专业人员点赞。
反思
如果下次遇到这种情况可以通过 VNC 登录,因为 VNC 登录不需要网络连接。
总结
这一次的故障从 2024-8- 24 14:43:00 开始,所有指标除了网络 IO 都显示极其大的变化,持续到 2024-8-24 20:11。
主要故障程序:Hfish。
故障原因未知。
已停止故障程序并且恢复所有业务。